ComfyUI-VibeVoice
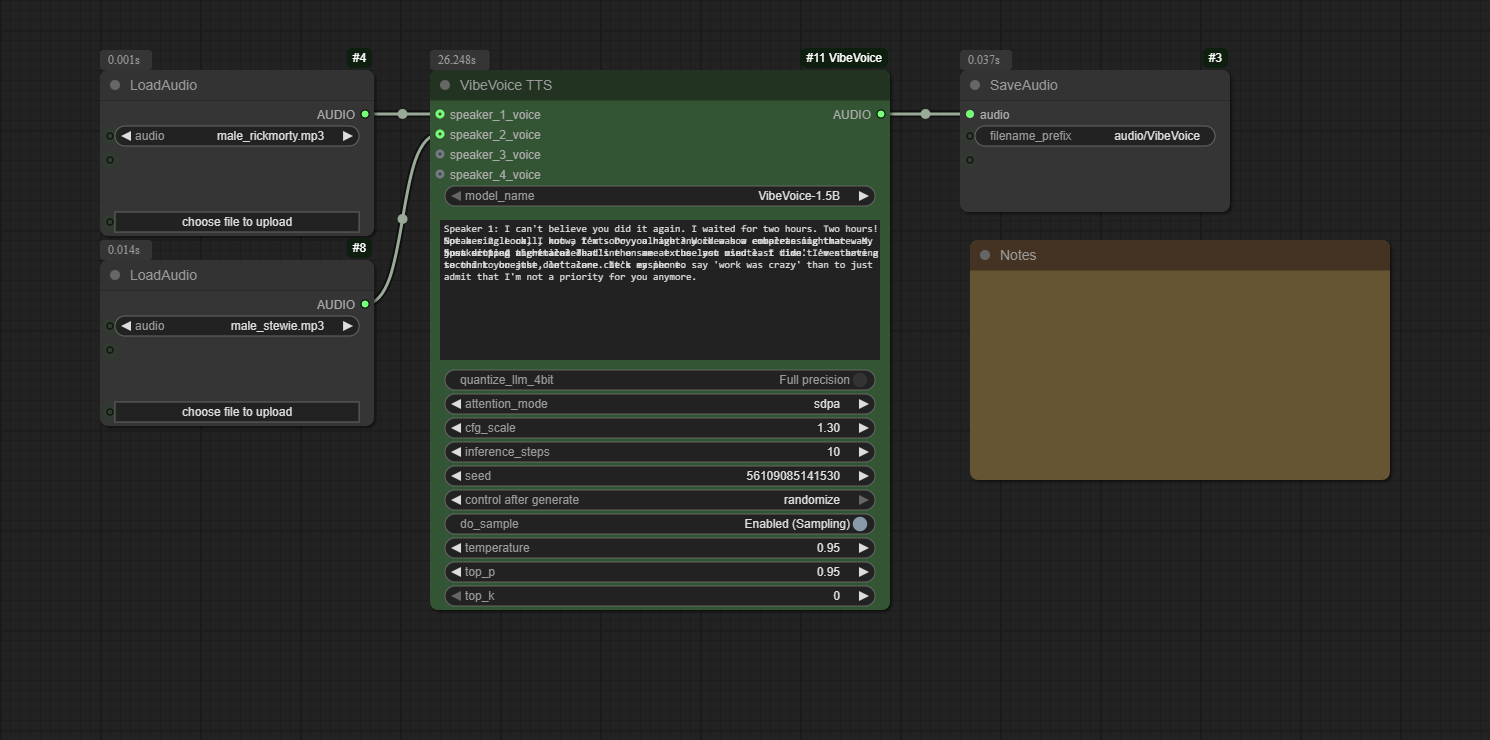
A custom node for ComfyUI that integrates Microsoft's VibeVoice, a frontier model for generating expressive, long-form, multi-speaker conversational audio.
Report Bug
·
Request Feature
[![Stargazers][stars-shield]][stars-url]
[![Issues][issues-shield]][issues-url]
[![Contributors][contributors-shield]][contributors-url]
[![Forks][forks-shield]][forks-url]
## About The Project
This project brings the power of **VibeVoice** into the modular workflow of ComfyUI. VibeVoice is a novel framework by Microsoft for generating expressive, long-form, multi-speaker conversational audio. It excels at creating natural-sounding dialogue, podcasts, and more, with consistent voices for up to 4 speakers.
The custom node handles everything from model downloading and memory management to audio processing, allowing you to generate high-quality speech directly from a text script and reference audio files.
**Key Features:**
* **Multi-Speaker TTS:** Generate conversations with up to 4 distinct voices in a single audio output.
* **Zero-Shot Voice Cloning:** Use any audio file (`.wav`, `.mp3`) as a reference for a speaker's voice.
* **Automatic Model Management:** Models are downloaded automatically from Hugging Face and managed efficiently by ComfyUI to save VRAM.
* **Fine-Grained Control:** Adjust parameters like CFG scale, temperature, and sampling methods to tune the performance and style of the generated speech.
* **4-Bit Quantization:** Run the large language model component in 4-bit mode to significantly reduce VRAM usage and improve speed on memory-constrained GPUs, especially for the 7B model.
* **Transformers 4.56+ Compatibility:** Fully backwards compatible with both older and newer versions of the Transformers library.
* **Force Offload Option:** Toggle to force model offloading from VRAM after generation to save memory between runs - now with improved ComfyUI compatibility.